The Calamu Process
Calamu’s patented process ensures that data is always available to authorized users and applications, and completely valueless to everyone else.
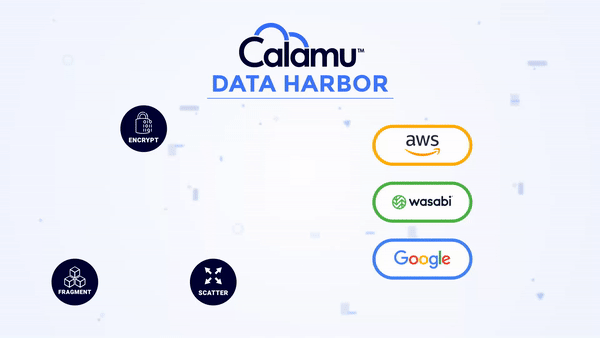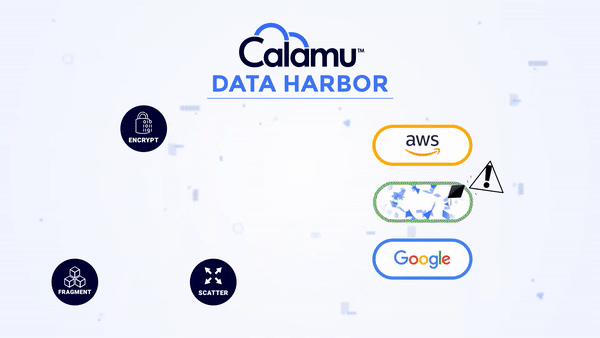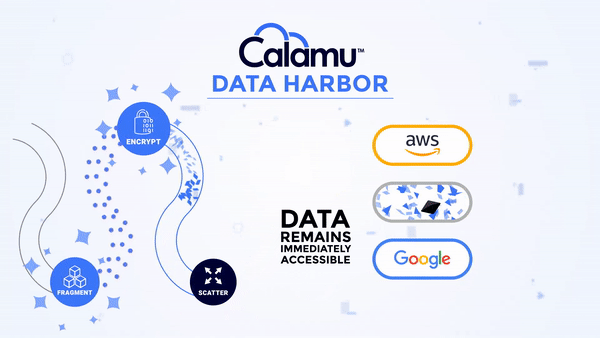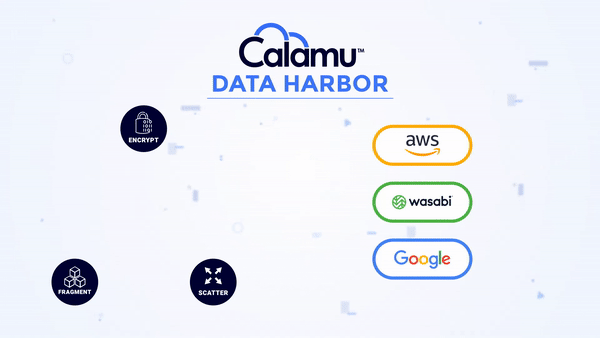
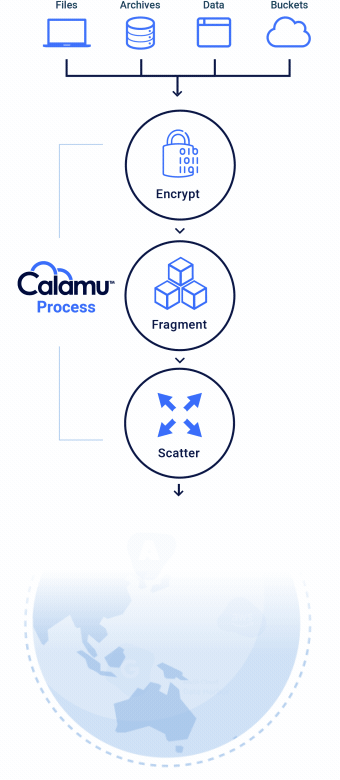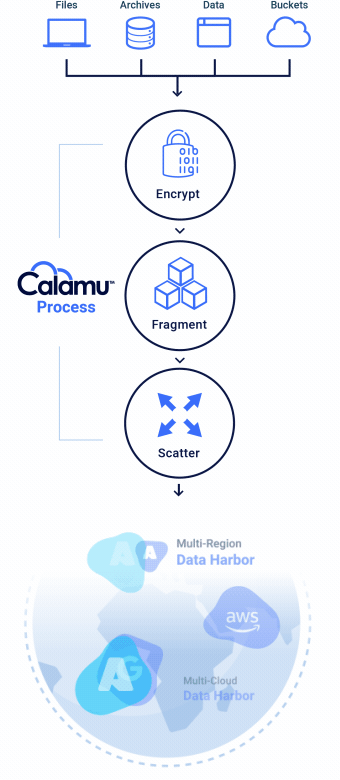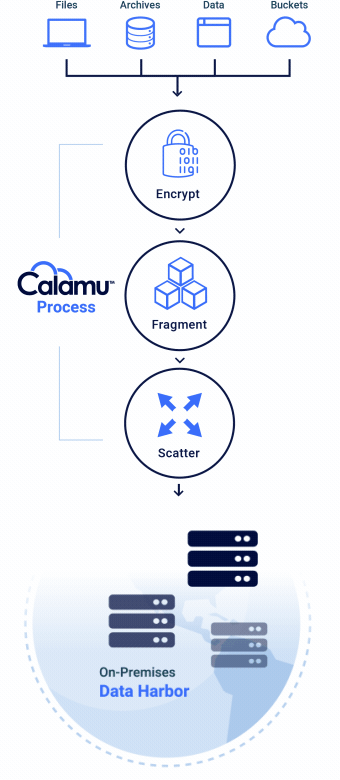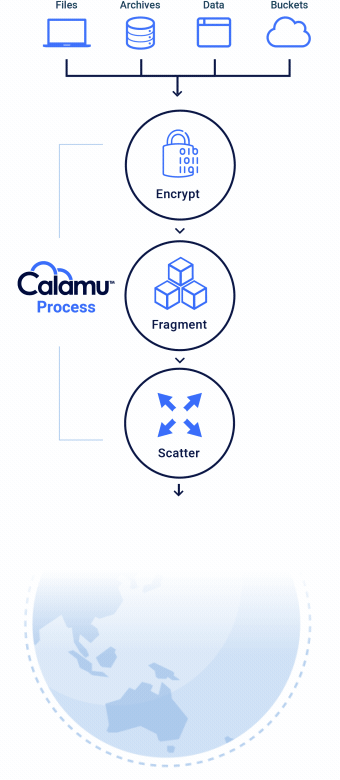
Eliminates Data Sensitivity
With a Data Harbor, your data is completely in your control no matter where it is.
No storage location contains all the components necessary to reconstitute the data, making it nearly impossible for information to be exposed or compromised. While at-rest, it's possible for information to not exist in a single geography anywhere in the world, known as jurisdiction independence. This greatly simplifies compliance with data privacy regulations like GDPR, DORA and others.


